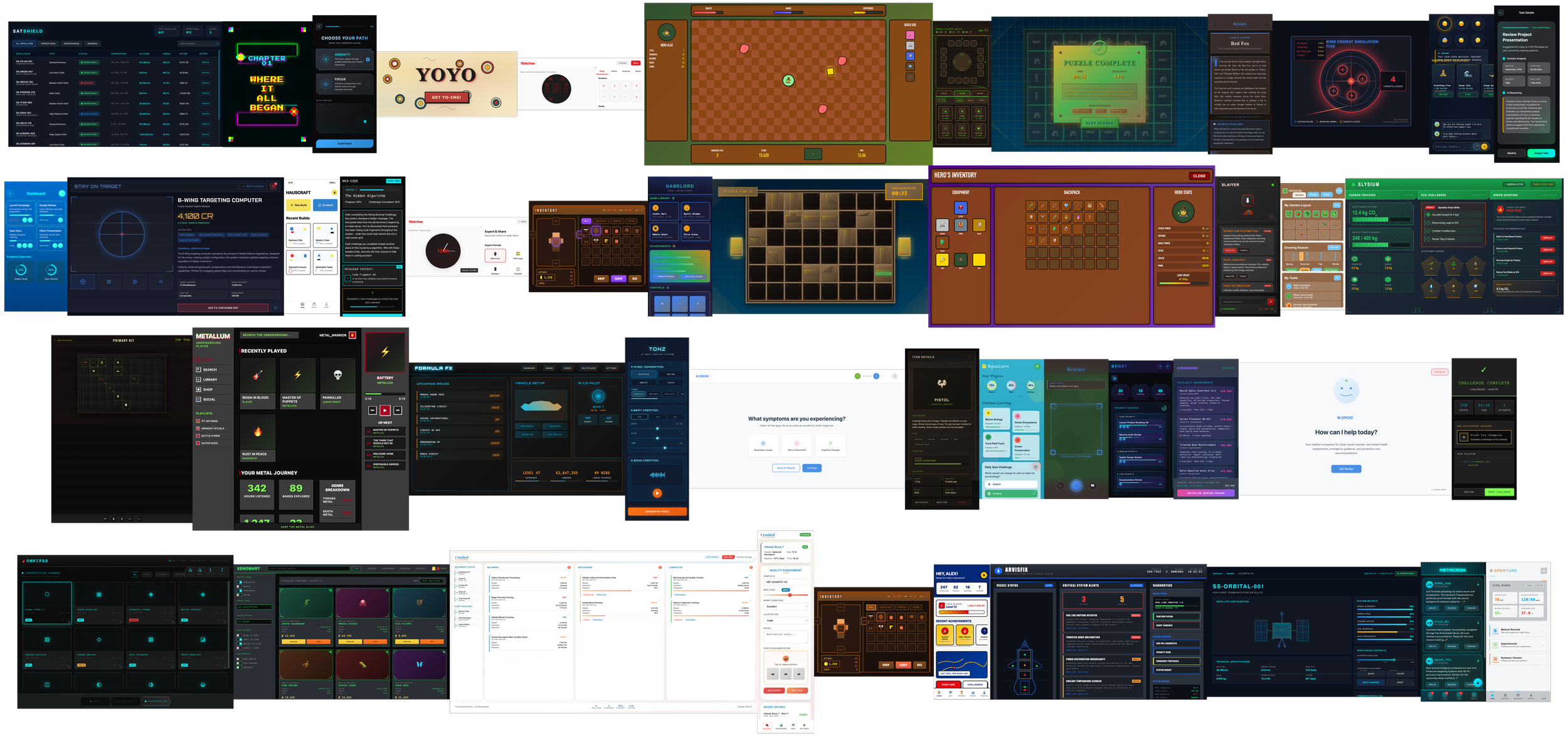
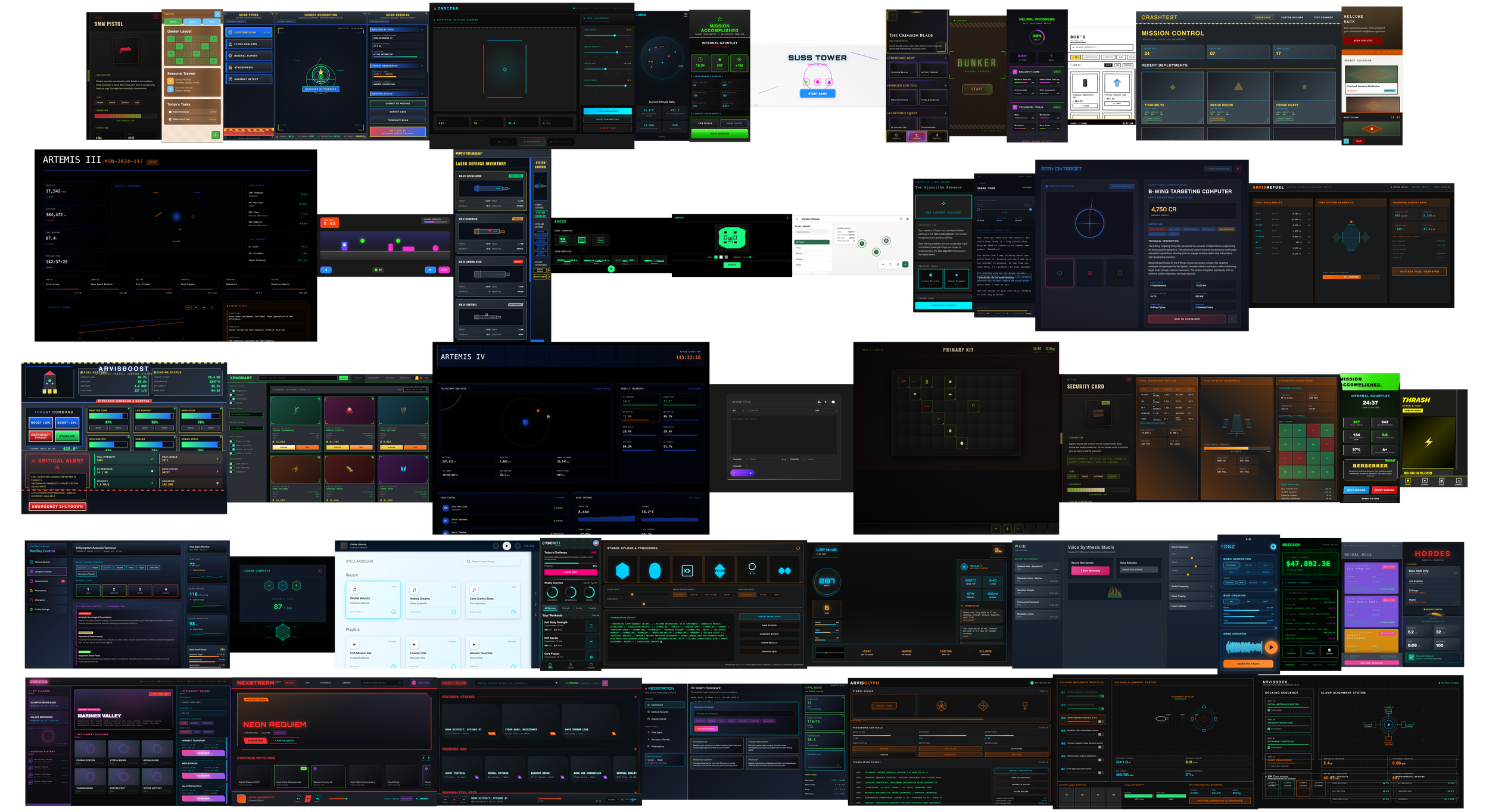
The "Mercor 100" RLHF Experiment
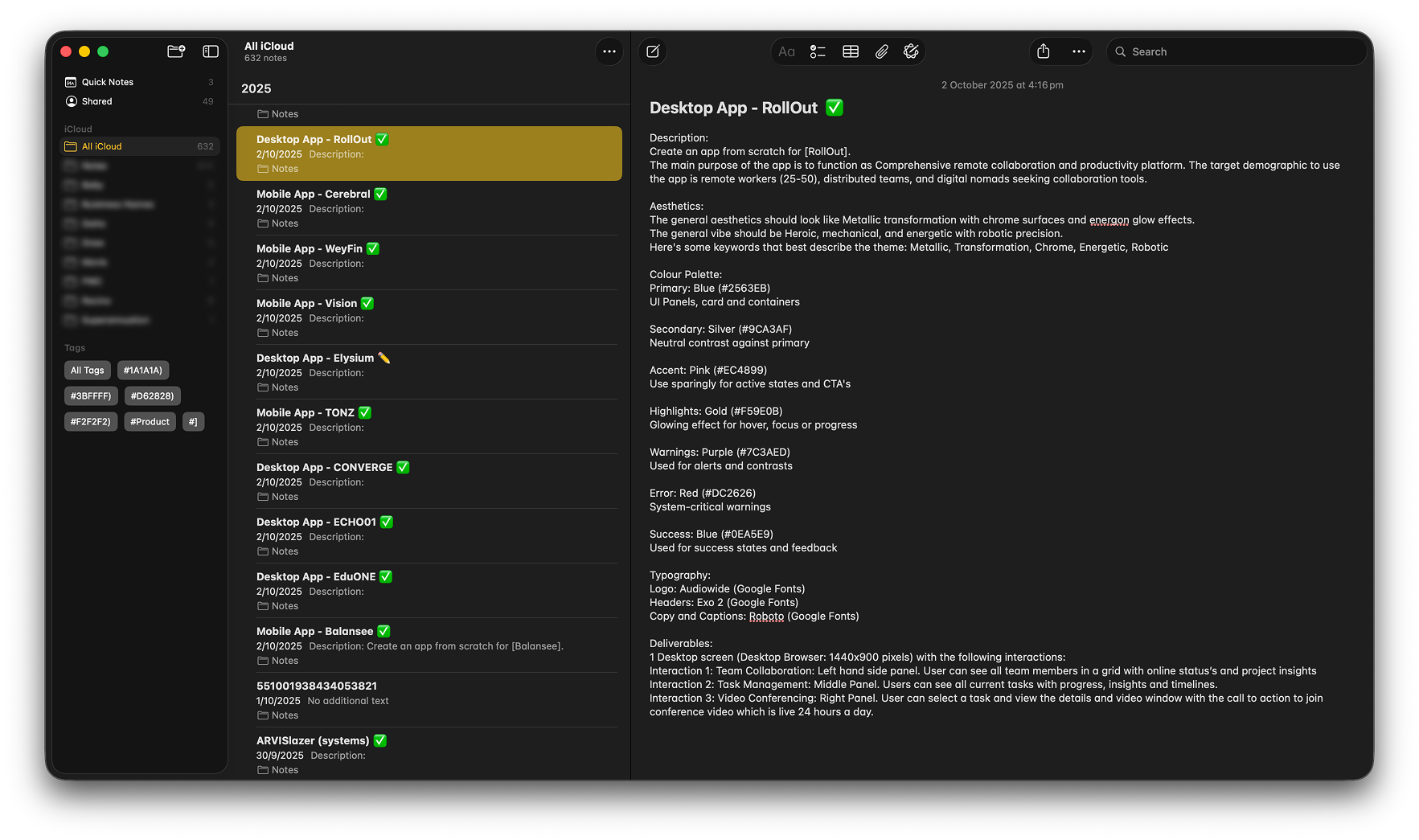
The Challenge: How do you train a closed-loop LLM to understand complex design governance without access to the outside world? At Mercor AI, I was tasked with "Vibe Coding" 100+ high-fidelity experiments in 4 weeks to stress-test and refine an internal model’s architectural decision-making.
The Environment: Zero-Scrape Constraints
Working within a proprietary, air-gapped ecosystem meant no external AI assistance and no web-scraping. Every output was the result of high-precision, manual prompt architecture.
The Solution: Architectural RLHF (Reinforcement Learning from Human Feedback)
My process involved developing a Dynamic Prompting Framework that evolved through a rigorous voting and feedback loop.
The A/B Benchmarking: For every prompt, I audited dual outcomes—voting on "Brief Proximity" vs. "Execution Quality."
The Feedback Loop: I provided detailed, granular critiques to the model to reduce hallucinations and improve its understanding of Mechanical Complexity.
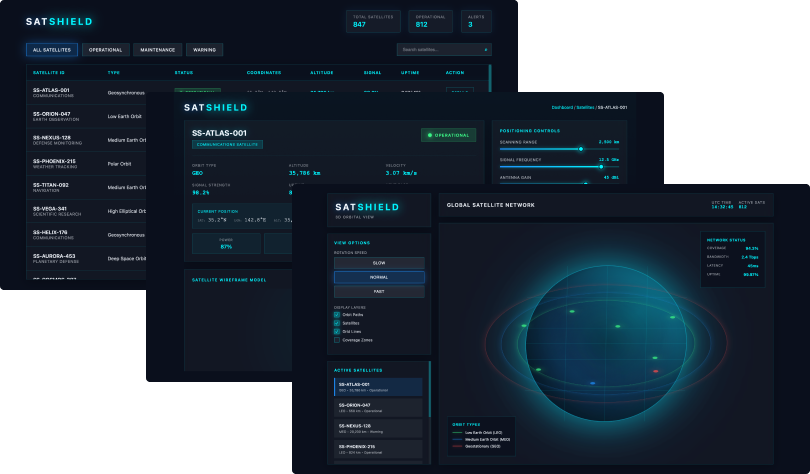
Systemic Steering: I integrated SVG asset calling, Google Font mapping, and proportional grid-guides directly into the prompt logic to "steer" the model toward production-ready results.
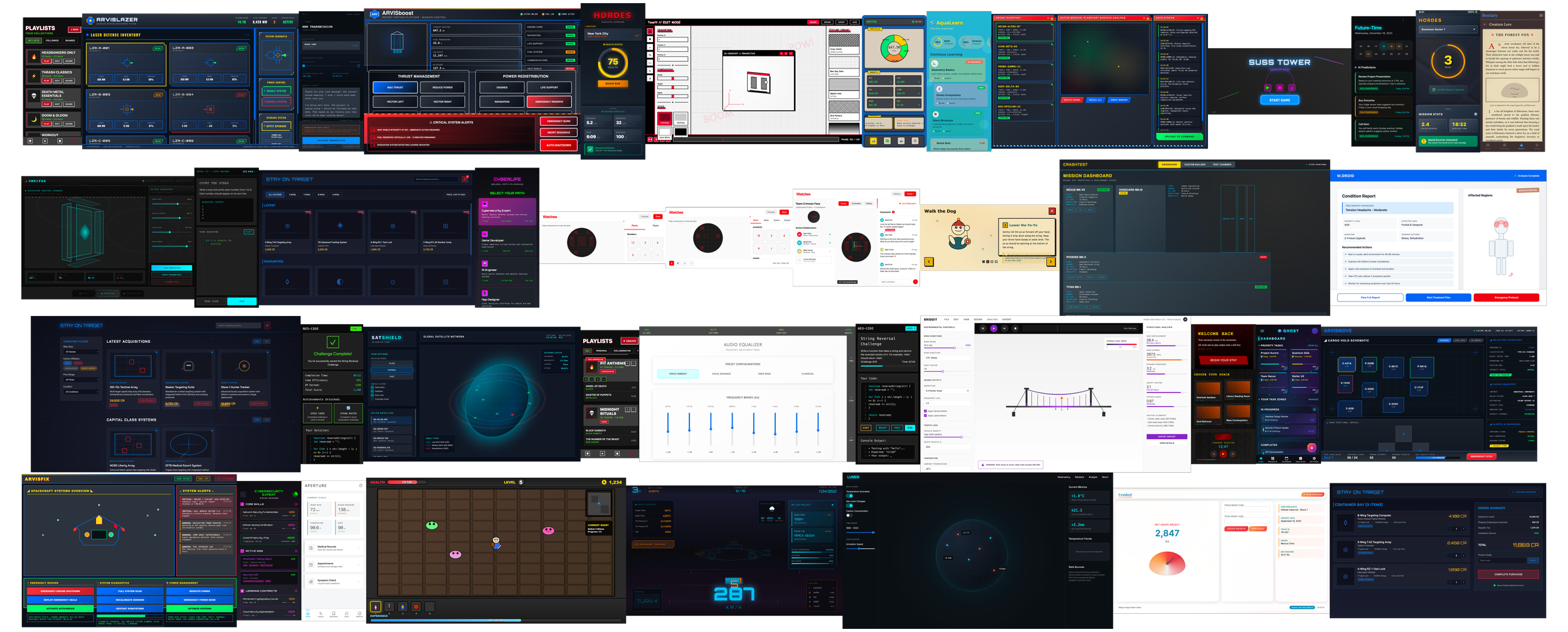
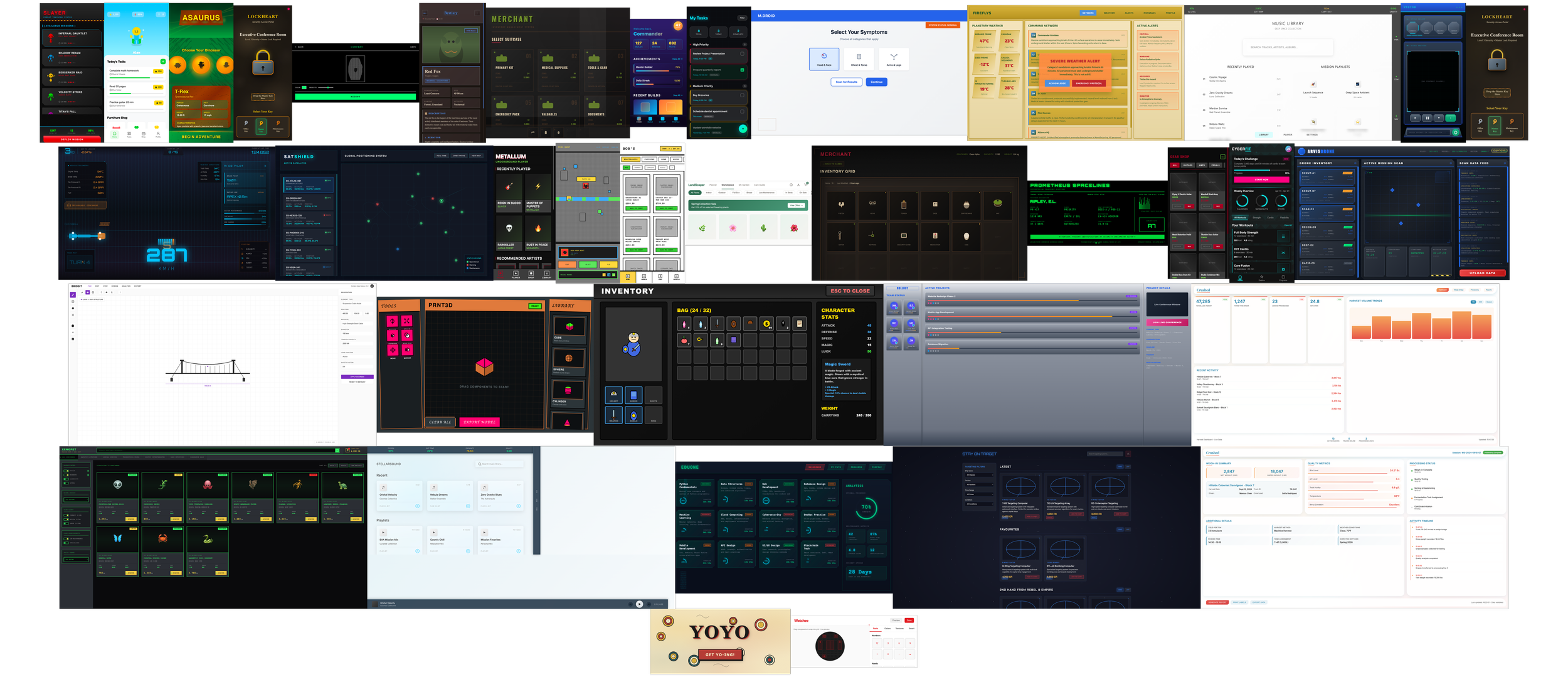
Orchestration Layers: As the experiment progressed, I moved from single-screen prompts to multi-screen frameworks, including interaction logic and animation states, all handled within the initial prompt load.
The Impact
Volume at Speed: Successfully navigated a high-velocity output requirement without sacrificing the depth of the feedback loop.
Governance Training: Contributed to the foundational design logic of a global, proprietary LLM.
New Tooling: This research led directly to the development of my own specialised prompting tools designed for deep-application and interactive system framing.
Key Focus: Generative Operations (GenOps), RLHF Training Logic, Design Governance, Proprietary System Architecture, Systemic Steering.